
RPC是一种方便的网络通信编程模型,由于和编程语言的高度结合,大大减少了处理网络数据的复杂度,让代码可读性也有可观的提高。但是RPC本身的构成却比较复杂,由于受到编程语言、网络模型、使用习惯的约束,有大量的妥协和取舍之处。本文就是通过分析几种流行的RPC实现案例,提供大家在设计RPC系统时的参考。
由于RPC底层的网络开发一般和具体使用环境有关,而编程实现手段也非常多样化,但不影响使用者,因此本文基本涉及如何实现一个RPC系统。
认识 RPC (远程调用)
我们在各种操作系统、编程语言生态圈中,多少都会接触过“远程调用”的概念。一般来说,他们指的是用简单的一行代码,通过网络调用另外一个计算机上的某段程序。比如:
- RMI——Remote Method Invoke:调用远程的方法。“方法”一般是附属于某个对象上的,所以通常RMI指对在远程的计算机上的某个对象,进行其方法函数的调用。
- RPC——Remote Procedure Call:远程过程调用。指的是对网络上另外一个计算机上的,某段特定的函数代码的调用。
远程调用本身是网络通信的一种概念,他的特点是把网络通信封装成一个类似函数的调用。网络通信在远程调用外,一般还有其他的几种概念:数据包处理、消息队列、流过滤、资源拉取等待。下面比较一下他们差异:
| 方案 | 编程方式 | 信息封装 | 传输模型 | 典型应用 |
|---|---|---|---|---|
| 远程调用 | 调用函数,输入参数,获得返回值。 | 使用编程语言的变量、类型、函数 | 发出请求,获得响应 | Java RMI |
| 数据包处理 | 调用Send()/Recv(),使用字节码数据,编解码,处理内容 | 把通信内容构造成二进制的协议包 | 发送/接收 | UDP编程 |
| 消息队列 | 调用Put()/Get(),使用“包”对象,处理其包含的内容 | 消息被封装成语言可用的对象或结构 | 对某队列,存入一个消息;取出一个消息 | ActiveMQ |
| 流过滤 | 读取一个流,或写出一个流,对流中的单元包即刻处理 | 单元长度很小的统一数据结构 | 连接;发送/接收;处理 | 网络视频 |
| 资源拉取 | 输入一个资源ID,获得资源内容 | 请求或响应都包含:头部+正文 | 请求后等待响应 | WWW |
针对远程调用的特点——调用函数。业界在各种语言下都开发过类似的方案,同时也有些方案是试图做到跨语言的。尽管远程调用在编程方式上,看起来似乎是最简单易用的,但是也有明显的缺点。所以了解清楚远程调用的优势和缺点,是决定是否要开发、或者使用远程调用这种模型的关键问题。
远程调用的优势有:
- 屏蔽了网络层。因此在传输协议和编码协议上,我们可以选择不同的方案。比如WebService方案就是用的HTTP传输协议+SOAP编码协议;而REST的方案往往使用HTTP+JSON协议。Facebook的Thrift甚至可以定制任何不同的传输协议和编码协议,你可以用TCP+Google Protocol Buffer,也可以用UDP+JSON……。由于屏蔽了网络层,你可以根据实际需要来独立的优化网络部分,而无需涉及业务逻辑的处理代码,这对于需要在各种网络环境下运行的程序来说,非常有价值。
- 函数映射协议。你可以直接用编程语言来书写数据结构和函数定义,取代编写大量的编码协议格式和分包处理逻辑。对于那些业务逻辑非常复杂的系统,比如网络游戏,可以节省大量定义消息格式的时间。而且函数调用模型非常容易学习,不需要学习通信协议和流程,让经验较浅的程序员也能很容易的开始使用网络编程。
远程调用的缺点:
- 增加了性能消耗。由于把网络通信包装成“函数”,需要大量额外的处理。比如需要预生产代码,或者使用反射机制。这些都是额外消耗CPU和内存的操作。而且为了表达复杂的数据类型,比如变长的类型string/map/list,这些都要数据包中增加更多的描述性信息,则会占用更多的网络包长度。
- 不必要的复杂化。如果你仅仅是为了某些特定的业务需求,比如传送一个固定的文件,那么你应该用HTTP/FTP协议模型。如果为了做监控或者IM软件,用简单的消息编码收发会更快速高效。如果是为了做代理服务器,用流式的处理会很简单。另外,如果你要做数据广播,那么消息队列会很容易做到,而远程调用这几乎无法完成。
因此,远程调用最适合的场景是:业务需求多变,网络环境多变。
RPC方案的核心问题
由于远程调用的使用接口是“函数”,所以要如何构建这个“函数”,就产生了三个方面需要决策的问题:
1 . 如何表示“远程”的信息
所谓远程,就是指网络上另外一个位置,那么网络地址就是必须要输入的部分。在TCP/IP网络下,IP地址和端口号代表了运行中程序的一个入口。所以指定IP地址和端口是发起远程调用所必需的。
然而,一个程序可能会运行很多个功能,可以接收多个不同含义的远程调用。这样如何去让用户指定这些不同含义的远程调用入口,就成为了另外一个问题。当然最简单的是每个端口一种调用,但是一个IP最多支持65535个端口,而且别的网络功能也可能需要端口,所以这种方案可能会不够用,同时一个数字代表一个功能也不太好理解,必须要查表才能明白。
所以我们必须想别的方法。在面向对象的思想下,有些方案提出了:以不同的对象来归纳不同的功能组合,先指定对象,再指定方法。这个想法非常符合程序员的理解方式,EJB就是这种方案的。一旦你确定了用对象这种模型来定义远程调用的地址,那么你就需要有一种指定远程对象的方法,为了指定对象,你必须要能把对象的一些信息,从被调用方(服务器端)传输给调用方(客户端)。
最简单的方案就是客户端输入一串字符串作为对象的“名字”,发给服务器端,查找注册了这个“名字”的对象,如果找到了,服务器端就会用某种技术“传输”这个对象给客户端,然后客户端就可以调用他的方法了。当然这种传输不可能是把整个服务器上的对象数据拷贝给客户端,而是用一些符号或者标志的方法,来代表这个服务器上的对象,然后发给客户端。
如果你不是使用面向对象的模型,那么远程的一个函数,也是必须要定位和传输的,因为你调用的函数必须先能找到,然后成为客户端侧的一个接口,才能调用。针对“远程对象”(这里说的对象包括面向对象的对象或者仅仅是 函数)如何表达才能在网络上定位;以及定位成功之后以什么形式供客户端调用,都是“远程调用”设计方案中第一个重要的问题。
2 . 函数的接口形式应该如何表示
远程调用由于受到网络通信的约束,所以往往不能完全的支持编程语言的所有特性。比如C语言函数中的指针类型参数,就无法通过网络传递出去。因此远程调用的函数定义,能用语言中的什么特性,不能用什么特性,是需要在设计方案是规定下来的。
这种规定如果太严格,会影响使用者的易用性;如果太宽泛,则可能导致远程调用的性能低下。如何去设计一种方式,把编程语言中的函数,描述成一个远程调用的函数,也是需要考虑的问题。很多方案采用了配置文件这种通用的方式,而另外一些方案可以直接在源代码中里面加特殊的注释。
一般来说,编译型语言如C/C++只能采用源代码根据配置文件生成的方案,虚拟机型语言如C#/JAVA可以采用反射机制结合配置文件(设置是在源代码中用特殊注释来代替配置文件)的方案,如果是脚本语言就更简单,有时候连配置文件都不需要,因为脚本自己就可以充当。总之远程调用的接口要满足怎样的约束,也是一个需要仔细考虑的问题。
3. 用什么方法来实现网络通信
远程调用最重要的实现细节,就是关于网络通信。用何种通信方式来承载远程调用的问题,细化下来就是两个子问题:用什么样的服务程序提供网络功能?用什么样的通信协议?
远程调用系统可以自己直接对TCP/IP编程来实现通信,也可以委托一些其他软件,比如Web服务器、消息队列服务器等等……也可以使用不同的网络通信框架,如Netty/Mina这些开源框架。通信协议则一般有两层:一个是传输协议,比如TCP/UDP或者高层一点的HTTP,或者自己定义的传输协议;另外一个是编码协议,就是如何把一个编程语言中的对象,序列化和反序列化成为二进制字节流的方案,流行的方案有JSON、Google Protocol Buffer等等,很多开发语言也有自己的序列化方案,如JAVA/C#都自带。以上这些技术细节,应该选择使用哪些,直接关系到远程调用系统的性能和环境兼容性。

以上三个问题,就是远程调用系统必须考虑的核心选型。根据每个方案所面对的约束不同,他们都会在这三个问题上做出取舍,从而适应其约束。但是现在并不存在一个“万能”或者“通用”的方案,其原因就是:在如此复杂的一个系统中,如果要照顾的特性越多,需要付出的成本(易用性代价、性能开销)也会越多。
下面,我们可以研究下业界现存的各种远程调用方案,看他们是如何在这三个方面做平衡和选择的。
业界方案举例
1. CORBA
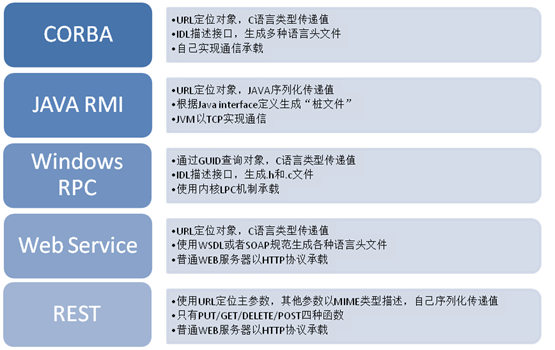
CORBA是一个“古老”的,雄心勃勃的方案,他试图在完成远程调用的同时,还完成跨语言的通信的任务,因此其复杂程度是最高的,但是它的设计思想,也被后来更多的其他方案所学习。在通信对象的定位上,它使用URL来定义一个远程对象,这是在互联网时代非常容易接受的。其对象的内容则限定在C语言类型上,并且只能传递值,这也是非常容易理解的。为了能让不同语言的程序通信,所以就必须要在各种编程语言之外独立设计一种仅仅用于描述远程接口的语言,这就是所谓的IDL:Interface Description Language 接口描述语言。
用这个方法,你就可以先用一种超然于所有语言之外的语言来定义接口,然后使用工具自动生成各种编程语言的代码。这种方案对于编译型语言几乎是唯一选择。CORBA并没有对通信问题有任何约定,而是留给具体语言的实现者去处理,这也许是他没有广泛流行的原因之一。
实际上CORBA有一个非常著名的继承者,他就是Facebook公司的Thrift框架。Thrift也是使用一种IDL编译生成多种语言的远程调用方案,并且用C++/JAVA等多种语言完整的实现了通信承载,所以在开源框架中是特别有号召力的一个。Thrfit的通信承载还有个特点,就是能组合使用各种不同的传输协议和编码协议,比如TCP/UDP/HTTP配合JSON/BIN/PB……这让它几乎可以选择任何的网络环境。
Thrift的模型类似下图,这里有的stub表示“桩代码”,就是客户端直接使用的函数形式程序;skeleton表示“骨架代码”,是需要程序员编写具体提供远程服务功能的模板代码,一般对模版做填空或者继承(扩展)即可。这个stub-skeleton模型几乎是所有远程调用方案的标配。
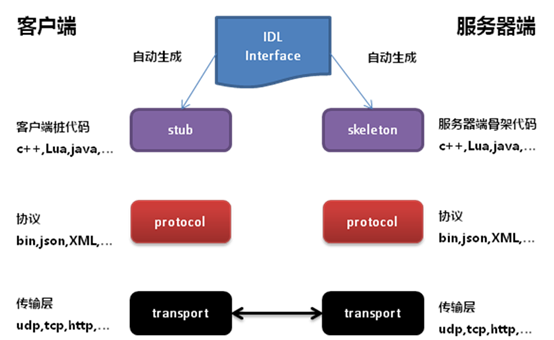
2. JAVA RMI
JAVA RMI是JAVA虚拟机自带的一个远程调用方案。它也是可以使用URL来定位远程对象,使用JAVA自带的序列化编码协议传递参数值。在接口描述上,由于这是一个仅限于JAVA环境下的方案,所以直接用JAVA语言的Interface类型作为定义语言。用户通过实现这个接口类型来提供远程服务,同时JAVA会根据这个接口文件自动生成客户端的调用代码供调用者使用。他的底层通信实现,还是用TCP协议实现的。在这里,Interface文件就是JAVA语言的IDL,同时也是skeleton模板,供开发者来填写远程服务内容。而stub代码则由于JAVA的反射功能,由虚拟机直接包办了。
这个方案由于JAVA虚拟机的支持,使用起来非常简单,完全按照标志的JAVA编程方法就可以轻松解决问题,但是这也仅仅能在JAVA环境下运行,限制了其适用的范围。鱼与熊掌不可兼得,易用性和适用性往往是互相冲突的。这和CORBA/Thrift追求最大范围的适用性有很大的差别,也导致了两者在易用性上的不同。
3. Windows RPC
Windows中对RPC支持是比较早和比较完善的。首先它通过GUID来查询对象,然后使用C语言类型作为参数值的传递。由于Windows的API主要是C语言的,所以对于RPC功能来说,还是要用一种IDL来描述接口,最后生成.h和.c文件来生产RPC的stub和skeleton代码。而通信机制,由于是操作系统自带的,所以使用内核LPC机制承载,这一点还是对使用者来说比较方便的。但是也限制了只能用于Windows程序之间做调用。
4. WebService & REST
在互联网时代,程序需要通过互联网来互相调用。而互联网上最流行的协议是HTTP协议和WWW服务,因此使用HTTP协议的Web Service就顺理成章的成为跨系统调用的最流行方案。由于可以使用大多数互联网的基础设施,所以Web Service的开发和实现几乎是毫无难度的。一般来说,它都会使用URL来定位远程对象,而参数则通过一系列预定义的类型(主要是C语言基础类型),以及对象序列化方式来传递。接口生成方面,你可以自己直接对HTTP做解析,也可以使用诸如WSDL或者SOAP这样的规范。在REST的方案中,则限定了只有PUT/GET/DELETE/POST四种操作函数,其他都是参数。
总结一下上面的这些RPC方案,我们发现,针对远程调用的三个核心问题,一般业界有以下几个选择:
- 远程对象定位:使用URL;或者使用名字服务来查找
- 远程调用参数传递:使用C的基本类型定义;或者使用某种预订的序列化(反序列化)方案
- 接口定义:使用某种特定格式的技术,直接按预先约定一种接口定义文件;或者使用某种描述协议IDL来生成这些接口文件
- 通信承载:有使用特定TCP/UDP之类的服务器,也有可以让用户自己开发定制的通信模型;还有使用HTTP或者消息队列这一类更加高级的传输协议
方案选型
在我们确定了远程调用系统方案几个可行选择后,自然就要明确一下各个方案的优缺点,这样才能选择真正合适需求的设计:
1. 对于远程对象的描述:使用URL是互联网通行的标准,比较方便用户理解,也容易添加日后需要扩展到内容,因为URL本身是一个由多个部分组合的字符串;而名字服务则老式一些,但是依然有他的好处,就是名字服务可以附带负载均衡、容灾扩容、自定义路由等一系列特性,对于需求复杂的定位比较容易实现。
2. 远程调用的接口描述:如果只限制于某个语言、操作系统、平台上,直接利用“隐喻”方式的接口描述,或者以“注解”类型注释手段来标注源代码,实现远程调用接口的定义,是最方便不过的。但是,如果需要兼容编译型语言,如C/C++,就一定要用某种IDL来生成这些编译语言的源代码了。
3.通信承载:给用户自己定制通信模块,能提供最好的适用性,但是也让用户增加了使用的复杂程度。而HTTP/消息队列这种承载方式,在系统的部署、运维、编程上都会比较简单,缺点就是对于性能、传输特性的定制空间就比较小。
分析完核心问题,我们还需要考虑一些适用性场景:
1. 面向对象还是面向过程:如果我们只是考虑做面向过程的远程调用,只需要定位到“函数”即可。而如果是面向对象的,则需要定位到“对象”。由于函数是无状态的,所以其定位过程可以简单到一个名字即可,而对象则需要动态的查找到其ID或句柄。
2.跨语言还是单一语言:单一语言的方案中,头文件或接口定义完全用一种语言处理即可,如果是跨语言的,就少不免要IDL
3. 混合式通信承载还是使用HTTP服务器承载:混合式承载可能可以用到TCP/UDP/共享内存等底层技术,可以提供最优的性能,但是使用起来必然非常麻烦。使用HTTP服务器的话,则非常简单,因为WWW服务的开源软件、库众多,而且客户端使用浏览器或者一些JS页面即可调试,缺点是其性能较低。
假设我们现在要为某种业务逻辑非常多变的领域,如企业业务应用领域,或游戏服务器端领域,去设计一个远程调用系统,我们可能应该如下选择:
1. 使用名字服务定位远程对象:由于企业服务是需要高可用性的,使用名字服务能在查询名字时识别和选择可用性服务对象。J2EE方案中的EJB(企业JavaBean)就是用名字服务的。
2. 使用IDL来生成接口定义:由于企业服务或游戏服务,其开发语言可能不是统一的,又或者需要高性能的编程语言如C/C++,所以只能使用IDL。
3.使用混合式通信承载:虽然企业服务看起来无需在很复杂的网络下运行,但是不同的企业的网络环境又可能是千差万别的,所以要做一个通用的系统,最好还是不怕麻烦提供混合式的通信承载,这样可以在TCP/UDP等各种协议中选择。
注:关注作者公众号,了解更多分布式架构、微服务、netty、MySQL、spring、性能优化、
等知识点。公众号:《JAVA架构进阶之路》
